On June 4, 2020, the USMLE announced an important change to the Step 1 and Step 2 CK tests. Or at least, an important change for some test-takers.
To clear the backlog of examinees after the Prometric closures this spring, the USMLE planned to have some students take the USMLE using “event-based testing” in July and August 2020.
(So far, so good.)
Problem was, they proposed allowing examinees at the event-based tests to take a shortened version of the USMLE due to the elimination of “unscored pretest items.” Meanwhile, examinees at Prometric would still take the classic (longer) version.
(Bad idea.)
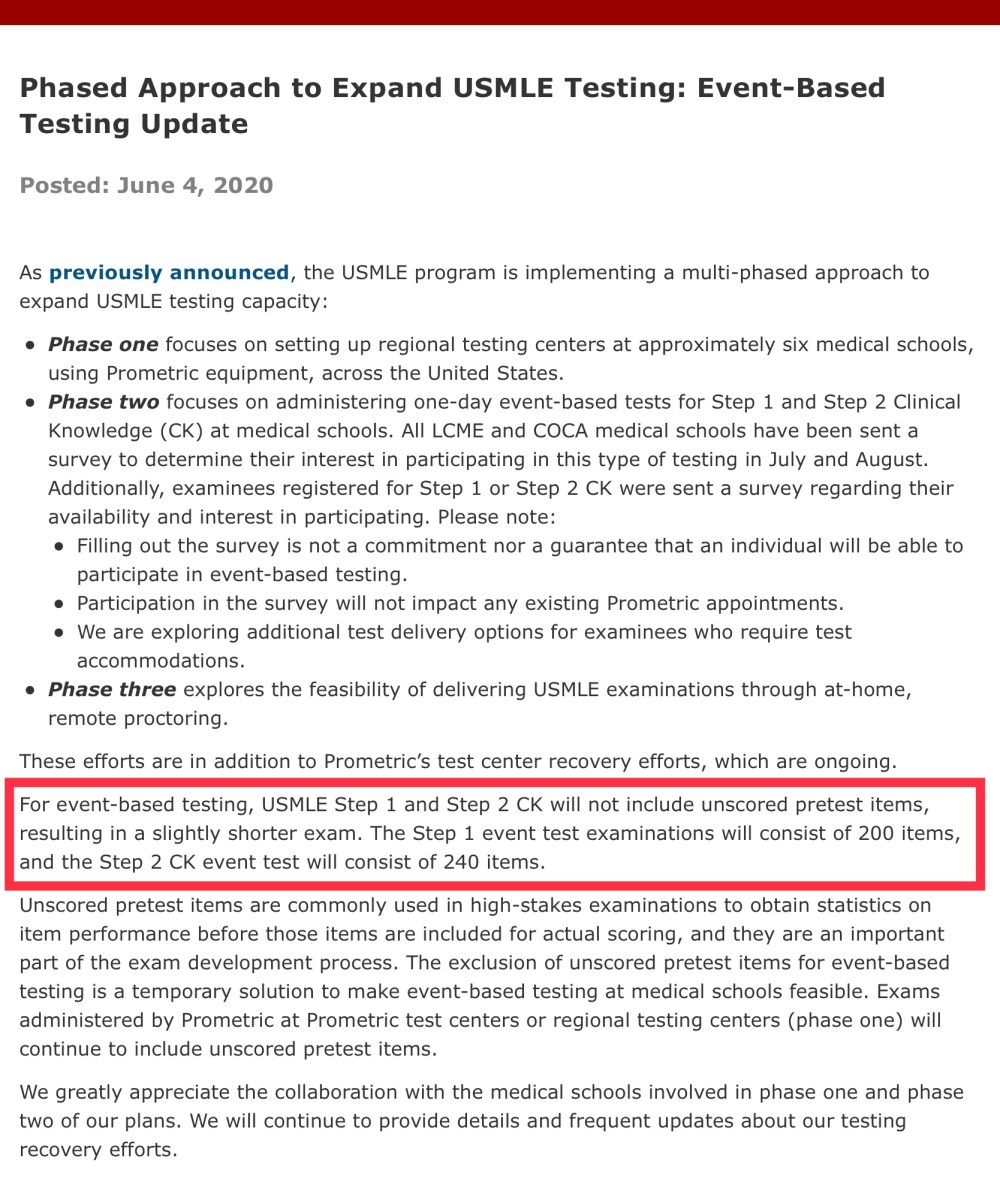
Announcement from the USMLE; June 4, 2020.
Somehow, the USMLE did not anticipate how upset people would get at their the proposal to de-standardize their signature standardized exam. Letting one group of test-takers take a 5-6 hour exam and another take a 7-8 hour exam damages the credibility of the test – if not its core validity.
I pointed this out on Twitter, along with several others. And fortunately, in the pile-on that ensued, the USMLE walked back its original announcement, stating that it would “reevaluate” this plan.
But as I scrolled through my mentions, something caught my eye.
There was small – but vocal – group of commenters who were not as upset about the test’s destandardization as they were angry about the fact that the USMLE had been “experimenting” on them without their consent.
This took me by surprise. As critical as I’ve been of the NBME, I don’t have any issue with their use of experimental test items. In fact, I think experimental items are essential for making an exam that serves their stated purpose. It occurred to me that some people may not realize why the USMLE includes these items, and how those data get used.
So here, I’m gonna give you a quick primer on how USMLE questions get written and tested, and explain how the data from experimental items are used to make the USMLE function as a licensure exam.
The birth of a question
Although the National Board of Medical Examiners is a corporation with over $150 million in annual revenue, its primary “product” – the questions on its tests – are written by unpaid volunteers.
Some medical school faculty – motivated by a good faith desire to make the world a better place or a quest to acquire academic capital – volunteer their time to write questions for the NBME.
Every full-grown USMLE question begins life as the flicker of an idea in some professor’s mind. Once she drafts the question, it’s evaluated by other volunteer faculty who serve on an item review committee. Each question item gets vetted for clarity, accuracy, relevance, and consistency with the USMLE format.

An example of drafting and editing a USMLE Step 2 CK question. (From the NBME Examiner, 2006 Vol 53 No 1.)
Once the item review committee is satisfied with the question, it enters “pretesting.” In this phase, the question appears on the USMLE and is administered to anywhere between a few hundred to a couple of thousand examinees.
Two quick sidenotes:
First, these experimental items should be indistinguishable from real USMLE questions. Sure, certain questions may deploy a new format and thus give themselves away as being experimental. But if the writing committee has done their job, the experimental items will look and feel like any other USMLE question. My point is, just because a question tests a concept that is not included in First Aid doesn’t mean it’s an experimental item. (I am deeply skeptical of the gunners on Student Doctor Network or Reddit who claim to have counted precisely the number of experimental items that were on their test. As you’ll see in the discussion below, experimental items that fail usually do so on the basis of psychometric performance, not faulty construction.)
Second, I’m going to use the word “experimental” when describing these questions. You may have noticed that the USMLE’s announcement does not use that term, preferring instead to call them “unscored pretest items.” I don’t like how that sounds.
It is true that items undergoing pretesting do not count toward an individual examinee’s score. However, the items are scored to generate internal data for the NBME.
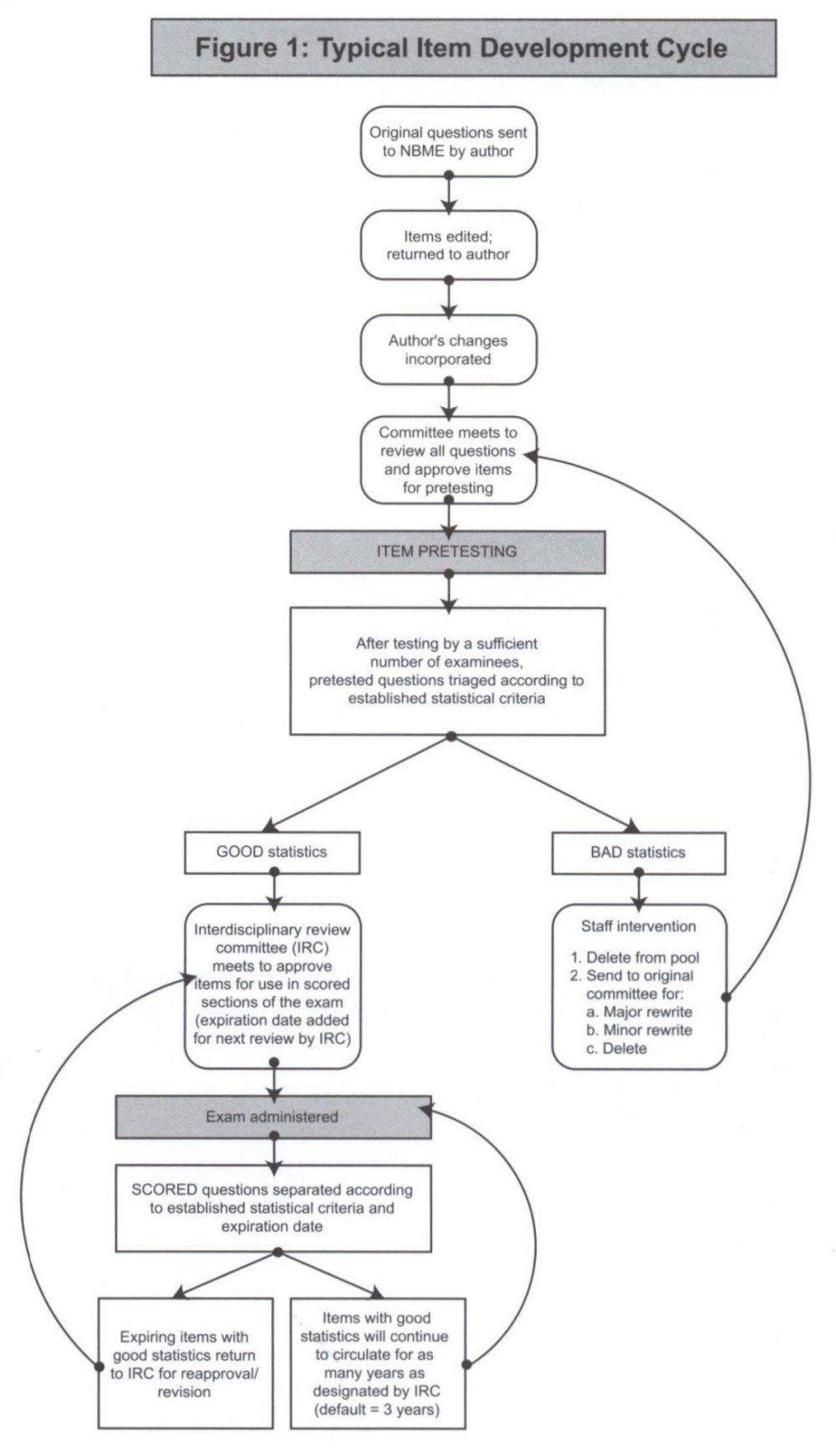
Only items with “GOOD statistics” get to appear on the USMLE. (From the NBME Examiner (2006 Vol 53 No 1.)
Above is a flow chart demonstrating what happens to items that undergo pre-testing. Some make it onto the test; some don’t.
However, left unmentioned is how, exactly, the NBME decides whether a question is good enough to appear on the USMLE? How do they determine “GOOD statistics” from “BAD statistics”?
To answer these questions, let’s work through some examples.
Imagine this…
Imagine you’re an NBME executive.
You’ve just come home from the Pyramid Club, where you and yours enjoyed $45 shots of tequila and dancing at eye-level with the city skyline. It’s been a long night, but you can’t call it quits yet: you still have 5 potential USMLE questions to review.
Fortunately, you don’t have to read the questions themselves – their content is irrelevant to the task at hand. All you’re concerned with are the data reports. They’ll tell you whether the question is ready for prime-time – or if it needs to be sent back to the shop.
You open up the first report, and see this.
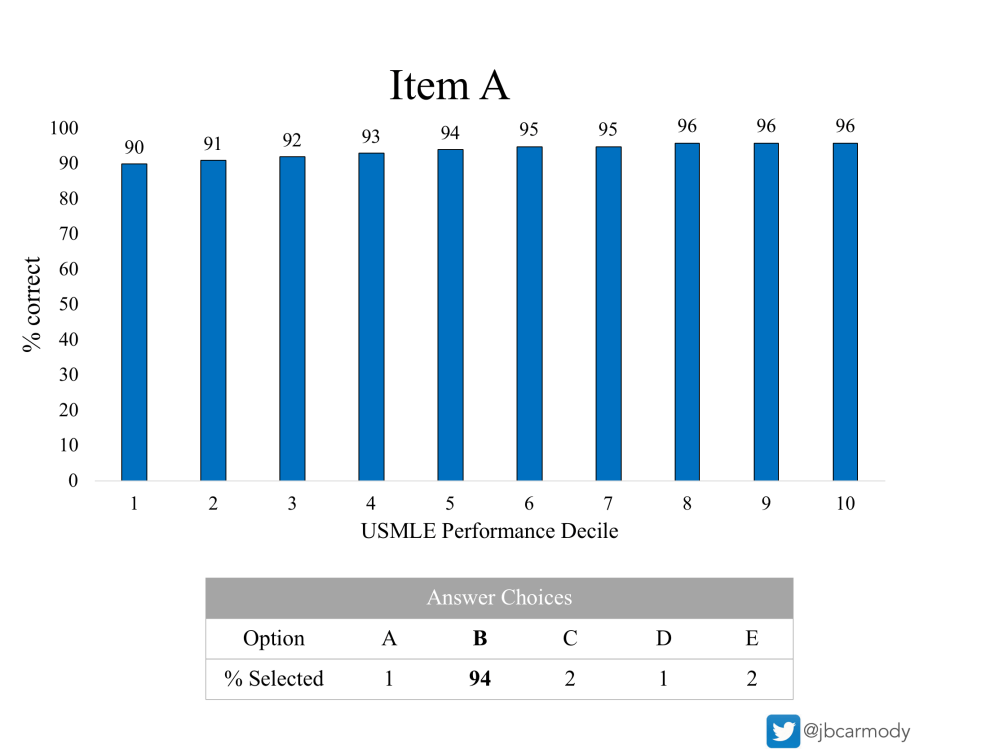
Item A.
It’s been a while since I’ve looked at one of these, you think to yourself as you get oriented.
The report contains two pieces of information.
The blue bars demonstrate the percentage of examinees who answered the question item correctly, grouped by the test-taker’s overall USMLE performance decile. (Using the current USMLE Score Interpretation Guidelines, test-takers in the first decile have a USMLE Step 1 score of < 205 or. Step 2 CK < 220; those in the top decile would have a Step 1 score better than ~255 or a Step 2 CK ~265.)
The grey box demonstrates the percentage of examinees who chose each answer choice. The correct answer is bolded. Thus, in the example above, 94% of examinees got Item A correct.
Now that you’re oriented, you snap back to the present. Ah, yes. Now, what to make of Item A…
Overall, 94% of test-takers answered it correctly.
Much too easy, you think to yourself.
Of course, that’s not exactly the real issue. The real issue is that a question item like this provides poor discrimination. The ideal USMLE question is one that all competent physicians would answer correctly and all incompetent charlatans would answer incorrectly. (The mere thought of a question with such perfect discrimination causes your lips to curl into a thin smile.)
Here, though, there’s only a 6-percentage-point difference between the best test-takers and the worst. That will never do. Better send it back to committee. Maybe they can make it a little more difficult, and that will separate the examinees.
On to Item B.
_

Item B.
Wow – Item B is tough. Only 45% of examinees answered it correctly! That ought to keep them on their toes, you chuckle.
And this question does do a good job of discriminating between high and low performers. (Note how examinees in the bottom decile got the item right only around half as often as those in the top decile.)
But, when your eyes glance upon the distribution of answer choices, you realize that this question won’t work out, either.
Forty-five percent of examinees chose the correct answer (E). However, another 45% chose a particular distractor (A). That’s awfully strong performance for an incorrect response. It probably means that the question needs another review by the commitee to ensure it’s not unfairly tricky or deliberately misleading – and to be absolutely certain that answer A is truly incorrect.
–

Item C.
Item C has a nice distribution in the answer choices: 62% answered correctly, with smaller fractions devoted to two of the distractors (A and B).
Still, your well-trained eye spots a problem: the U-shaped distribution of correct responses across performance deciles.
For a given test item, you expect that your best test-takers would answer correctly more often than other groups. And indeed, that’s what you see here. Students in the top 10% of all USMLE test-takers answered Item C correctly 78% of the time.
But here’s what’s weird: 75% of the worst test-takers also answered Item C correctly. How did that happen? Is there some unusual element of the question stem that allows otherwise low-performers to guess the correct answer (such as repeating a particular word from the question stem in the answer choice)? Does the clinical vignette allow someone using wrong-headed pathophysiological thinking to end up with the right answer? It’s hard to know, but something isn’t right with this question. Better send it back to committee, too.
_
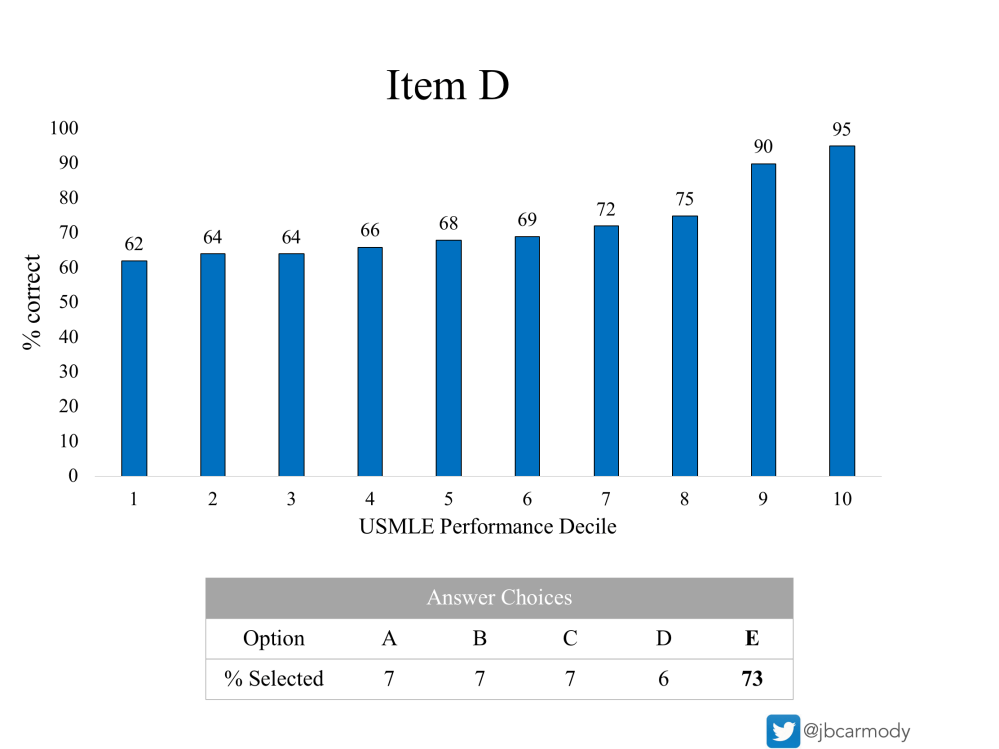
Item D.
Now here’s a good lookin’ question.
Overall, 73% of examinees answered Item D correctly. Plus, the distribution of incorrect responses is almost equal across the four distractors. You’ve always loved distractors. The fact that each of these pulls in 6-7% of test-takers tells you that each is a plausible response – or that the question has completely stumped some students, and they’ve just guessed at random. (Either way is fine – what you don’t want to see is a distractor that no one chooses. If a distractor gets a 0% response, you’re gonna send it back to committee every time.)
Still, when you look closely at the distribution of performance by USMLE score decile, you realize that this question nonetheless is not ideal for your test.
This question provides its greatest discrimination at the upper end of the score range. There’s a 20-point difference between the 8th and the 10th decile, but only a 6-7 point difference in correct responses between examinees in the lowest decile and those who score at the median.
Put another way, this item is more useful in distinguishing a superior test-taker from an above average one than it is in distinguishing an average student from one who is incompetent.
And ultimately, that’s not what your test is for.
Remember, the purpose of the USMLE is to make a binary determination of an examinee’s competence for medical licensure. The USMLE is not intended to distinguish the 75th percentile student from the 95th percentile student (though residency program directors have mistakenly chosen to use it that way). Matter of fact, because you specifically choose questions based on their ability to provide low-end discrimination, it’s not even really clear what very high scores mean in a psychometric sense.
So you set aside Item D for now – and break out in a broad grin when you see…
_
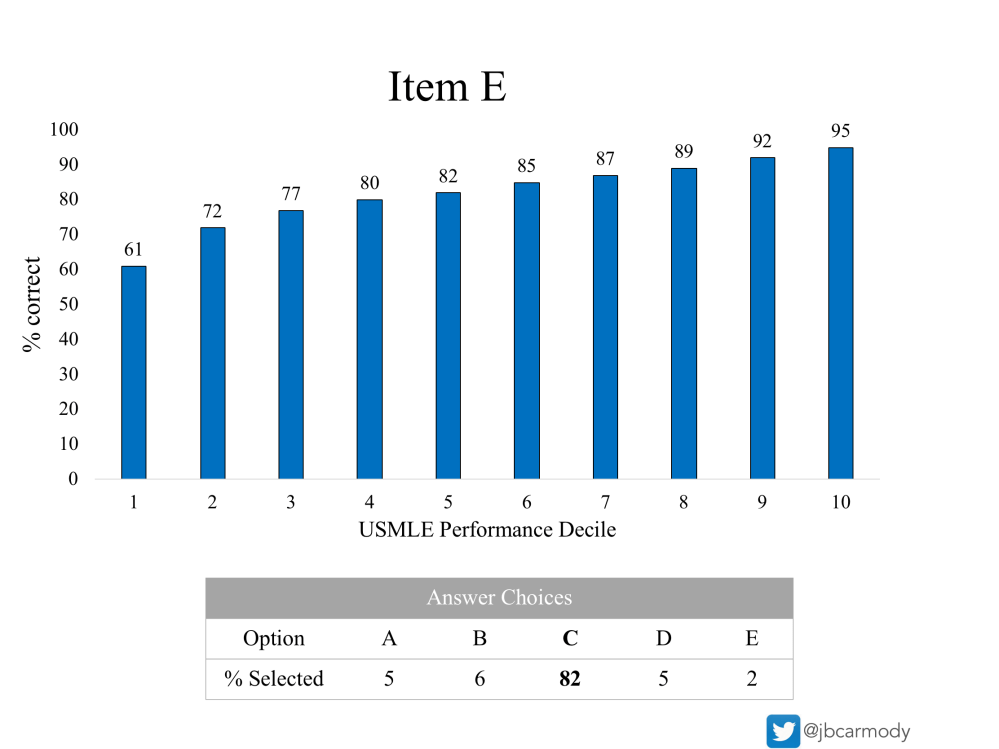
Item E.
Here, 82% of examinees get the question right. But notice how Item E has its finest discrimination at the low end of the range. It actually has some discrimination in the upper end, too – but that low-end discrimination is the feature that a question has to have if it wants to make it onto the real test.
This one’s ready to send down to the boys at Prometric, you think.
And now, with your work complete – and while still basking in the warm glow of such a perfect question – you drift off into a peaceful slumber.
–
Other uses of experimental data
Of course, this little exercise doesn’t capture all of the statistical evaluation that the NBME does on experimental items. For instance, they also evaluate questions to ensure that there are not systematic differences by gender or race, for example. (Any significant variation there is almost certainly unwarranted and signifies a poor test item.)
The performance distribution data are also used to help set the USMLE’s passing standard. Subject matter experts review these performance data when deciding what percentage of examinees should get each item correct, which is used to determine the minimum number of items that must be answered correctly to pass.
The point is, the USMLE’s use of experimental items is necessary and useful. (Now, whether they have to test so many experimental items – up to 25% of some test forms – is an separate question that remains up for debate.)
YOU MIGHT ALSO LIKE:
How is the three-digit USMLE score calculated?
A peek inside the USMLE sausage factory: setting the Step 1 minimum passing score
